
The summary distills case IDs as signals of system dynamics, exposing recurring patterns across contexts. It notes fragmented exchanges, early cascades, and bottlenecks that emerge under load. Through standardized logging and latency variance, it tracks throughput, utilization, and error distributions to reveal stability boundaries. The implications inform latency budgeting, RPO/RTO targets, and capacity planning, guiding resilient design. The discussion points to persistent variance and cross-domain governance, inviting further examination of how these factors shape reliable performance.
What These Case IDs Reveal About System Behavior
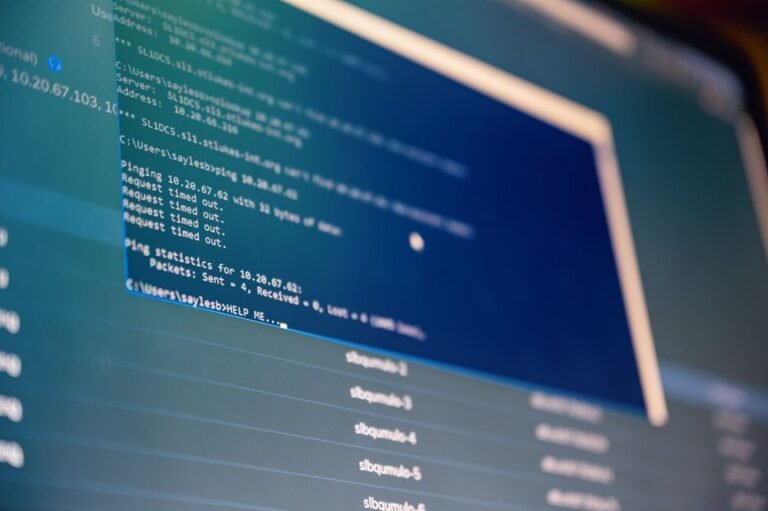
The Case IDs provide a concise lens into system behavior, revealing consistent patterns and outliers across operational contexts.
Case IDs indicate fragmented communication as a recurring signal, where incomplete exchanges destabilize coordination.
Early incidents trigger delay cascades, propagating latency through adjacent modules and timelines.
This systematic view supports targeted mitigation, clarifying causality and guiding disciplined, freedom-conscious optimization without blaming individuals.
Patterns, Bottlenecks, and Performance Trends Across Datasets
Patterns, bottlenecks, and performance trends across datasets reveal where contention arises and how throughput degrades under load. Across multiple collections, response latency escalates with utilization, while error distribution widens in saturated segments. Patterns indicate disproportionate impact on peak paths, suggesting targeted optimization. System behavior stabilizes where load balance improves, yet lingering variance persists, demanding continuous monitoring and disciplined capacity planning.
Methodologies for Analyzing Communication Workflows
What methodologies best illuminate the flow of communication processes, and how can they be applied consistently across heterogeneous environments? Systematic measurement frameworks assess events, queues, and feedback loops, enabling cross-domain comparability. Analytical approaches focus on latency variance and throughput distribution, supported by standardized logging, time synchronization, and artifact tagging. Results inform comparators, dashboards, and governance without implying design prescriptions or optimization bias.
Practical Implications for Design, Reliability, and Optimization
Practical implications arise at the intersection of design, reliability, and optimization, translating measurement outcomes into actionable constraints and standards. The analysis translates data into robust architectures, balancing performance with resilience.
Focused on disaster recovery and latency budgeting, design choices formalize failure tolerance, RPO/RTO targets, and resource allocation. Systematic evaluation informs trade-offs, guiding repeatable, auditable improvements without constraining freedom of innovation.
Frequently Asked Questions
How Were Privacy and Security Considerations Addressed in Data Collection?
The study employed privacy safeguards, data anonymization, and access controls, while routine security audits assessed controls and vulnerabilities, ensuring robust privacy protections and compliance. Data handling prioritized confidentiality, with vigilant logging and continuous evaluation of risk across systems.
What Software Tools Were Used for Real-Time vs. Post-Hoc Analysis?
Satire aside, the analysis used real time tools for instantaneous monitoring and post hoc tools for retrospective assessment, enabling systematic evaluation; both categories supported concise, analytical decision-making in a freedom-seeking audience.
Are There Notable Anomalies That Require Further Investigation Beyond Datasets?
Yes, notable anomalies exist beyond datasets, warranting further scrutiny. Anomaly patterns suggest structured deviations, while Data gaps complicate interpretation. The analysis advocates targeted verification, cross-checks, and enhanced monitoring to isolate root causes and confirm persistence or transience.
How Do Deployment Environments Affect Observed System Behavior?
Deployment environments influence observed system behavior through hardware, software stacks, and network conditions, shaping data collection and timing. Security considerations affect sampling fidelity, while real time analysis demands consistent instrumentation and minimal overhead to preserve representative measurements.
What Are the Cost Implications of Proposed Optimization Strategies?
Cost implications hinge on the chosen optimization strategies; upfront investments, maintenance, and potential throughput shifts determine total value. Systematically evaluating trade-offs ensures informed decisions, balancing performance gains with budgetary constraints and long-term financial feasibility for freedom-minded stakeholders.
Conclusion
The case IDs collectively suggest nuanced system fragility rather than overt failure, highlighting suboptimal resource contention and latent bottlenecks. Across datasets, gradual throughput compression and widening error distributions point to capacity-to-demand imbalances rather than abrupt breakdowns. The patterns encourage a cautious, incremental optimization approach: tune latency budgets, strengthen governance, and implement proactive monitoring. In essence, resilience rests on measured adjustments, clear ownership, and disciplined capacity planning to preempt cascading disturbances without signaling alarm.